



CVAT, your go-to computer vision annotation tool, now supports the YOLOv8 dataset format.
Version 2.17.0 of CVAT is currently live. Among the many changes and bug fixes, CVAT also introduced support for YOLOv8 datasets for all open-source, SaaS, and Enterprise customers. Starting now, you export annotated data to be compatible with YOLOv8 models.
What is the YOLOv8 Dataset Format?
YOLOv8, developed by Ultralytics, is the latest version of the YOLO (You Only Look Once) object detection series of models. YOLOv8 is designed for:
- Classification: Classifying or organizing an entire image into a set of predefined classes;

- Object Detection: Detecting, locating, and identifying the class of object in the image or visual data.

- Pose Estimation: Identifying the location and orientation of a person or object within an image by recognizing specific keypoints (also referred to as interest points).

- Oriented Bounding Boxes: A step further than object detection and introduce an extra angle to locate objects more accurately in an image.

- Instance Segmentation: Pixel-accurate segmentation of objects or people in an image or visual data.

With the help of CVAT’s data labeling and annotation tools, YOLOv8 models can be trained to perform the functions as accurately as possible.
What are the Benefits of Using the YOLOv8 Model for Computer Vision?
Ultralytics has used the knowledge and experience garnered from previous iterations of their AI models to create the latest and most advanced YOLOv8. The benefits of using YOLOv8 include, but are certainly not limited to:
- Highly accurate object detection;
- Versatility when it comes to detecting multiple objects, classifying and segmenting them, and detecting keypoints within images;
- Efficient, as the YOLOv8 has been optimized for efficient hardware usage and doesn’t require much computing power to run;
- Open-source means that the YOLOv8 is always evolving and being built by a passionate community of developers and all its features are easily accessible;
- And a lot more that would require a much longer list than this.
Which Industries Can Benefit from Training YOLOv8 Models?
A trained YOLOv8 model can then be used for a variety of tasks. The functionality that YOLOv8 computer vision models can provide will benefit the following industries.
Computer vision and AI models trained to detect various objects related to automotive are the way of the future in the automotive industry. Self-driving vehicles and traffic management are just a few of the ways that YOLOv8 models will benefit the automotive industry.
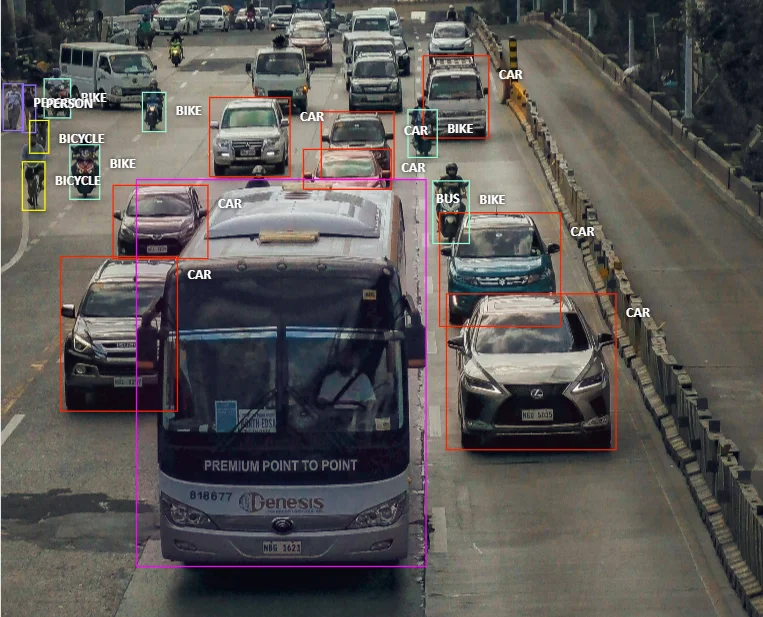
The YOLOv8 object detection model can also offer significant functionality for security. Thanks to highly accurate object tracking and pose estimation, YOLOv8 models can detect intrusions and monitor for unregistered activities or prohibited objects within a given area.

Using computer vision in retail and logistics will improve the efficiency at which stores maintain their supply and stock. They can also use YOLOv8's powerful object detection function to detect which shelves need to be restocked to improve customer experience.
Naturally, the robotics industry greatly benefits from AI models with accurate computer vision, as it helps significantly when it comes to problem-solving. With each advancement in computer vision, problem-solving robots get more and more sophisticated as a result.

In construction and architecture, computer vision can identify weak support, foundational problems, and other structural errors. This can help construction crews to detect potentially disastrous errors before any serious problems occur. On top of that, visual surveillance can be paired with AI to help construction managers detect safety hazards before they take place.

There are ton of functions for many other industries when it comes to Ultralytics' YOLOv8 model. For now, these are among the most popular use cases for this tech.
Understanding the Technical Details of the YOLOv8 Dataset Format
The YOLOv8 dataset format uses a text file for each image, where each line corresponds to one object in the image.
Each line includes five values for detection tasks: class_id, center_x, center_y, width, and height. These coordinates are normalized to the image size, ensuring consistency across varying image dimensions.
For tasks like pose estimation, the YOLOv8 format also includes additional keypoint coordinates. Segmentation tasks require the use of polygons or masks, represented by a series of points that define the object boundary. Additionally, oriented bounding boxes can be rotated, which helps in annotating objects not aligned with the image axes.
Dataset Structure
The YOLOv8 dataset typically includes the following components:
<dataset directory>/
├── data.yaml # configuration file
├── train.txt # list of train subset image paths
│
├── images/
│ ├── train/ # directory with images for train subset
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── image3.jpg
│ │ └── ...
├── labels/
│ ├── train/ # directory with annotations for train subset
│ │ ├── image1.txt
│ │ ├── image2.txt
│ │ ├── image3.txt
│ │ └── ...
- Images Folder: This folder contains the images you are training the model on. These images are referenced by the corresponding annotation files.
- Annotations: Each image has a corresponding .txt file with the same name located in the annotations folder. The file structure for detection tasks looks like this:
# <image_name>.txt:
# content depends on format
# YOLOv8 Detection:
# label_id - id from names field of data.yaml
# cx, cy - relative coordinates of the bbox center
# rw, rh - relative size of the bbox
# label_id cx cy rw rh
1 0.3 0.8 0.1 0.3
2 0.7 0.2 0.3 0.1
# YOLOv8 Oriented Bounding Boxes:
# xn, yn - relative coordinates of the n-th point
# label_id x1 y1 x2 y2 x3 y3 x4 y4
1 0.3 0.8 0.1 0.3 0.4 0.5 0.7 0.5
2 0.7 0.2 0.3 0.1 0.4 0.5 0.5 0.6
# YOLOv8 Segmentation:
# xn, yn - relative coordinates of the n-th point
# label_id x1 y1 x2 y2 x3 y3 ...
1 0.3 0.8 0.1 0.3 0.4 0.5
2 0.7 0.2 0.3 0.1 0.4 0.5 0.5 0.6 0.7 0.5
# YOLOv8 Pose:
# cx, cy - relative coordinates of the bbox center
# rw, rh - relative size of the bbox
# xn, yn - relative coordinates of the n-th point
# vn - visibility of n-th point. 2 - visible, 1 - partially visible, 0 - not visible
# if second value in kpt_shape is 3:
# label_id cx cy rw rh x1 y1 v1 x2 y2 v2 x3 y3 v3 ...
1 0.3 0.8 0.1 0.3 0.3 0.8 2 0.1 0.3 2 0.4 0.5 2 0.0 0.0 0 0.0 0.0 0
2 0.3 0.8 0.1 0.3 0.7 0.2 2 0.3 0.1 1 0.4 0.5 0 0.5 0.6 2 0.7 0.5 2
# if second value in kpt_shape is 2:
# label_id cx cy rw rh x1 y1 x2 y2 x3 y3 ...
1 0.3 0.8 0.1 0.3 0.3 0.8 0.1 0.3 0.4 0.5 0.0 0.0 0.0 0.0
2 0.3 0.8 0.1 0.3 0.7 0.2 0.3 0.1 0.4 0.5 0.5 0.6 0.7 0.5
# Note, that if there are several skeletons with different number of points,
# smaller skeletons are padded with points with coordinates 0.0 0.0 and visibility = 0
- data.yaml: This configuration file defines the dataset structure for training. It includes paths to the images and annotation files and lists all class names. An example of a data.yaml file looks like this:
path: ./ # dataset root dir
train: train.txt # train images (relative to 'path')
# YOLOv8 Pose specific field
# First number is the number of points in a skeleton.
# If there are several skeletons with different number of points, it is the greatest number of points
# Second number defines the format of point info in annotation txt files
kpt_shape: [17, 3]
# Classes
names:
0: person
1: bicycle
2: car
# ...
This lightweight and modular format allows for flexibility and scalability in your machine-learning pipeline. It also means that it can undertake a wide range of computer vision tasks, including object detection, pose estimation, segmentation, and oriented bounding boxes. For more technical details and in-depth usage, you can explore the full YOLOv8 format documentation.
How to Use the YOLOv8 Dataset Format in CVAT
Exporting YOLOv8 Datasets
After completing annotations in CVAT, exporting them in a YOLOv8 format is straightforward. Here’s how you can do it:
- Export Your Dataset: Once your annotations are ready, CVAT allows you to export them in YOLOv8 format, ensuring they are perfectly structured for use in YOLOv8 models. This includes annotations for detection, pose, oriented bounding boxes, and segmentation tasks. For detailed instructions on exporting your dataset, you can refer to the Exporting Annotations Guide.
- Train Your YOLOv8 Model: With your annotations exported, you can now directly integrate them into Ultralytics' YOLOv8 training pipeline. The dataset will be ready to train your model for detection, pose estimation, or segmentation tasks without the need for conversion. For further guidance on training your YOLOv8 models using Python, check out the Ultralytics YOLOv8 Python Usage Guide.
Importing YOLOv8 Datasets
In addition to exporting datasets, CVAT also supports importing datasets that are already in the YOLOv8 format. This feature allows you to bring external datasets and annotations into CVAT for further refinement or use in different projects. You can import both annotations and images for detection, oriented bounding boxes, segmentation, and pose estimations.
To learn more about how to import YOLOv8 datasets and annotations, follow the detailed instructions in our Dataset Import Guide.
F.A.Q.
Which CVAT users have access to YOLOv8 support?
All CVAT users, including open-source, SaaS, and Enterprise, have access to annotation tools for the YOLOv8 computer vision model.
How good is YOLOv8 object detection?
A YOLOv8 computer vision model trained with data annotated through CVAT can be very accurate in identifying various objects in visual data. YOLOv8 models can identify object borders down to the pixel, making them incredibly powerful when it comes to object detection.
What functions do YOLOv8 models perform in computer vision?
As listed above, YOLOv8's functions include classification, object detection, pose estimation, oriented bounding boxes, and instance segmentation.
Start Using YOLOv8 in CVAT Today!
The additional support for YOLOv8 dataset formats is a major milestone for CVAT. All open-source, SaaS customers and Enterprise clients are welcome to try out CVAT to help you train a YOLOv8 model for all manner of computer vision uses.
For more information, visit our YOLOv8 format documentation.





.svg)
.png)

.png)









.png)